はじめに
どうも、Caruです。 最近、GitHubのAppsやAPI周りを色々調べてるのですが、色々ありすぎて、正直わけわからんって感じです。
そんな中、GitHubのAPIを使ってブログを構築する方法が思っていたより良さそうなので紹介します。
基本構造
とりあえず使ってみようということで、シンプルな構造を考えてみました!
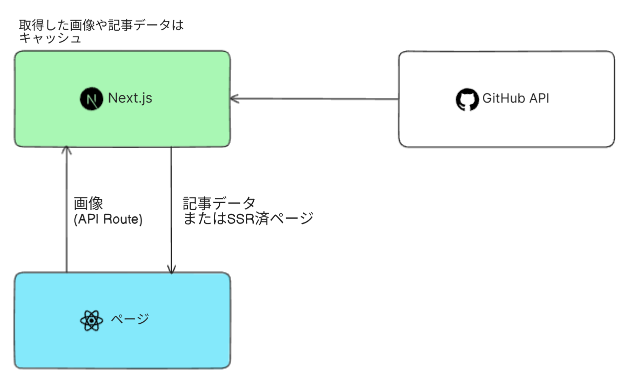
GitHub APIを使って、投稿を取得して、それをキャッシュして、配信という流れです。データベースやオブジェクトストレージがいらないので、かなりシンプルに仕上っていると思います。
ここでは、SSRなので、データが変更されても比較的早く反映されますが、トラフィックが多い場合は、SSGやISRすると良いかもしれませんね(WebHookなどでRevalidateをトリガーするとか)。
使用するAPI
GitHubには、2種類のAPIがあって、それぞれ長所と短所があります。 独断と偏見で書いたので、参考程度にお願いします。
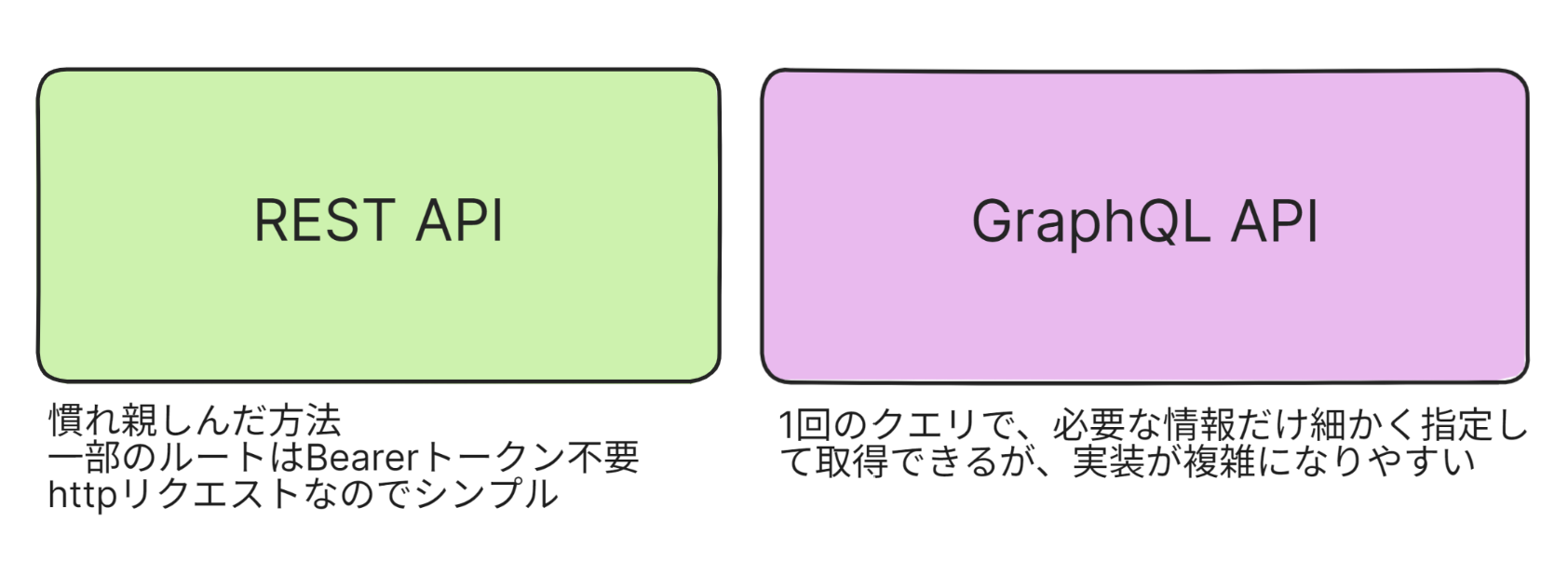
今回は、RAWコンテンツを取得するのに便利なGraphQL APIを使った例を紹介したいと思います!
なぜGraphQLが良いのか
実際のコードを見ると、GraphQLの利点がよくわかります。
REST APIの場合(複数リクエストが必要):
// 1. ディレクトリ内のファイル一覧を取得
const filesResponse = await fetch(`https://api.github.com/repos/${owner}/${repo}/contents/${articlesDir}`);
const files = await filesResponse.json();
// 2. 各ファイルの内容を個別に取得(N+1問題)
const articles = await Promise.all(
files.map(async (file) => {
const contentResponse = await fetch(file.download_url);
const content = await contentResponse.text();
return { name: file.name, content };
})
);GraphQLの場合(1回のリクエストで完結):
const { repository } = await graphqlClient(`
{
repository(owner: "${owner}", name: "${repo}") {
tree: object(expression: "main:${articlesDir}") {
... on Tree {
entries {
name
type
object {
... on Blob {
text
}
}
}
}
}
}
}
`);GraphQLなら1回のリクエストで、ファイル一覧とその内容を同時に取得できるので、非常に効率が良いです。(見た目は良くないですが...)
私の実装では、GraphQLで取得したデータからRAWコンテンツを取り出して、Frontmatterをパースして、サイトの記事リストに表示しています。
実装例
実際のキャッシュ機能付きの実装はこちら:
const getCachedArticlesList = cache(
queryArticlesList,
[`${owner}-${repo}-${articlesDir}`],
{ tags: ["posts"] }
);Next.jsのunstable_cacheと組み合わせることで、GitHub APIへのアクセスを最小限に抑えています。
コード
今回作成した実装は以下のGitHubリポジトリにあります。
まとめ
GitHubのAPIを使ってブログを構築する方法が思っていたより良さそうなので紹介しました。
新しい技術ブログの形として使ってみてはいかがでしょうか?
ご覧いただきありがとうございました!
この記事がおもしろかったよっていう方は、ぜひXのフォローやいいねをお願いします!

はじめに
どうも、Caruです。 最近、GitHubのAppsやAPI周りを色々調べてるのですが、色々ありすぎて、正直わけわからんって感じです。
そんな中、GitHubのAPIを使ってブログを構築する方法が思っていたより良さそうなので紹介します。
基本構造
とりあえず使ってみようということで、シンプルな構造を考えてみました!
GitHub APIを使って、投稿を取得して、それをキャッシュして、配信という流れです。データベースやオブジェクトストレージがいらないので、かなりシンプルに仕上っていると思います。
ここでは、SSRなので、データが変更されても比較的早く反映されますが、トラフィックが多い場合は、SSGやISRすると良いかもしれませんね(WebHookなどでRevalidateをトリガーするとか)。
使用するAPI
GitHubには、2種類のAPIがあって、それぞれ長所と短所があります。 独断と偏見で書いたので、参考程度にお願いします。
今回は、RAWコンテンツを取得するのに便利なGraphQL APIを使った例を紹介したいと思います!
なぜGraphQLが良いのか
実際のコードを見ると、GraphQLの利点がよくわかります。
REST APIの場合(複数リクエストが必要):
// 1. ディレクトリ内のファイル一覧を取得
const filesResponse = await fetch(`https://api.github.com/repos/${owner}/${repo}/contents/${articlesDir}`);
const files = await filesResponse.json();
// 2. 各ファイルの内容を個別に取得(N+1問題)
const articles = await Promise.all(
files.map(async (file) => {
const contentResponse = await fetch(file.download_url);
const content = await contentResponse.text();
return { name: file.name, content };
})
);GraphQLの場合(1回のリクエストで完結):
const { repository } = await graphqlClient(`
{
repository(owner: "${owner}", name: "${repo}") {
tree: object(expression: "main:${articlesDir}") {
... on Tree {
entries {
name
type
object {
... on Blob {
text
}
}
}
}
}
}
}
`);GraphQLなら1回のリクエストで、ファイル一覧とその内容を同時に取得できるので、非常に効率が良いです。(見た目は良くないですが...)
私の実装では、GraphQLで取得したデータからRAWコンテンツを取り出して、Frontmatterをパースして、サイトの記事リストに表示しています。
実装例
実際のキャッシュ機能付きの実装はこちら:
const getCachedArticlesList = cache(
queryArticlesList,
[`${owner}-${repo}-${articlesDir}`],
{ tags: ["posts"] }
);Next.jsのunstable_cacheと組み合わせることで、GitHub APIへのアクセスを最小限に抑えています。
コード
今回作成した実装は以下のGitHubリポジトリにあります。
まとめ
GitHubのAPIを使ってブログを構築する方法が思っていたより良さそうなので紹介しました。
新しい技術ブログの形として使ってみてはいかがでしょうか?
ご覧いただきありがとうございました!
この記事がおもしろかったよっていう方は、ぜひXのフォローやいいねをお願いします!